
2024.02.02
FNN 네트워크
FNN 네트워크 문제
- 분류
- binary classification
- multi classification
- 회귀
FNN 구조
- FNN Input layer
- 입력데이터를 벡터 형태로 받아들인다.
- FNN Activation Function
- 활성화 함수는 다양하다.
- 수학적으로는 심플하나 연산적으로는 매우 복잡하여 속도가 느린편이다.
- Gradient Vanishing 문제 발생에 대한 문제도 있다.
- ReLU계열
- RNN 계열에서는 잘 사용하지 않으나 FNN에서는 이 계열을 사용한다.
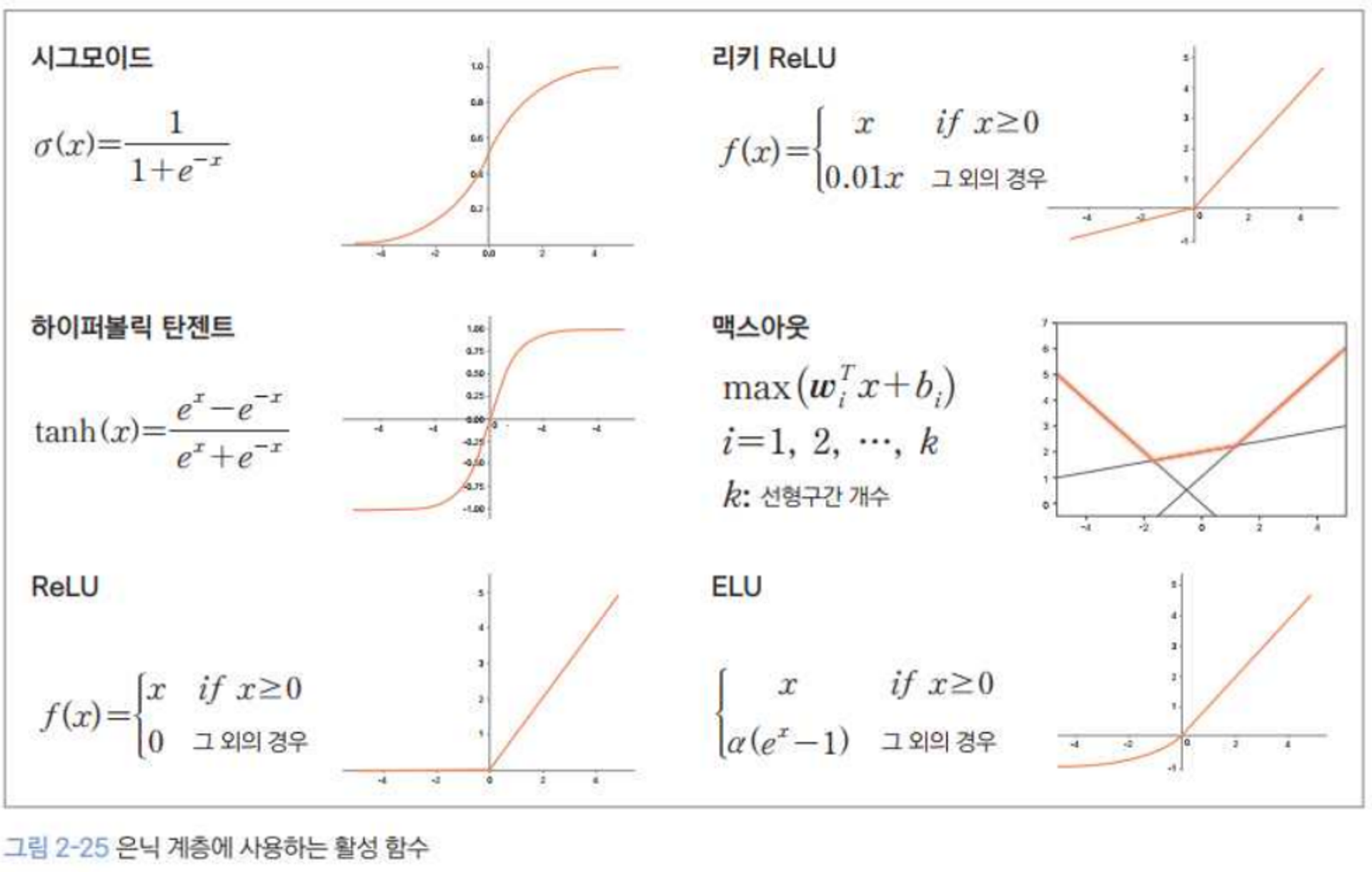
활성 함수의 종류
시그모이드, 하이퍼볼릭 탄젠트를 제외하고는 계산속도를 조금 더 빠르게 하기 위해 선형을 빙자한 비선형을 제시한다.
실습
Fashion MNIST: 의상관련된 이미지 구별을 위한 데이터셋 활용
import tensorflow as tf
import pandas as pd
# 데이터 셋 불러오기
fashion_mnist = tf.keras.datasets.fashion_mnist
fashion_mnist
# 데이터 셋 분리: train/test
(train_X, train_y, (test_X, test_y) = fashion_mnist.load_data()
print(train_X.shape)
print(train_y.shape)
print(test_X.shape)
print(test_y.shape)
=> (60000,28,28), (60000,), (60000,28,28), (60000,)
# resize, 흑백 변환, 해상도 변환 등의 전처리 적용
# 생략
# MinMaxScaler 적용
train_X = train_X/255.0
test_X= test_X/255.0# 1) 직접 모델 설계 방식 적용
model = tf.keras.Sequential(
[
# 입력
tf.keras.layers.Flatten(input_shape = (28,28)),
tf.keras.layers.Dense(units=128, activation='relu'), # AF = relu
# 출력
tf.keras.layers.Dense(units = 10, activation='softmax')
# 10 종류 분류
]
)
# 2) 모델의 설계도를 도면상 확인
model.summary()
# 학습 방향 설정
model.compile = (
optimizer= tf.keras.optimizers.Adam(),
loss = 'categorical_crossentropy' # 원핫인코딩 방식
metrics=["accuracy"]
)
history = model.fit(
train_X,
tf. keras.utils.to_categorical(train_y, num_classese = 10),
epoch = 100, # 여러번 학습
batch_size = 256, # 데이터의 크기
validation_split = 0.25 # 중간 평가, 저장
)
# ============================================================================#
# 결과 확인
import matplotlib.pyplot as plt
# 수행 결과 그래프로 확인
plt.subplot(1,2,1) # loss
plt.plot(history.history["loss"], "b-", label="train_loss")
plt.plot(history.history["val_loss"], "r-", label="val_loss")
plt.xlabel("Epoch")
plt.legend()
plt.subplot(1,2,2) # metrics : accuracy
plt.plot(history.history["accuracy"], "b-", label="train_accuracy")
plt.plot(history.history["val_accuracy"], "r-", label="val_accuracy")
plt.xlabel("Epoch")
plt.legend()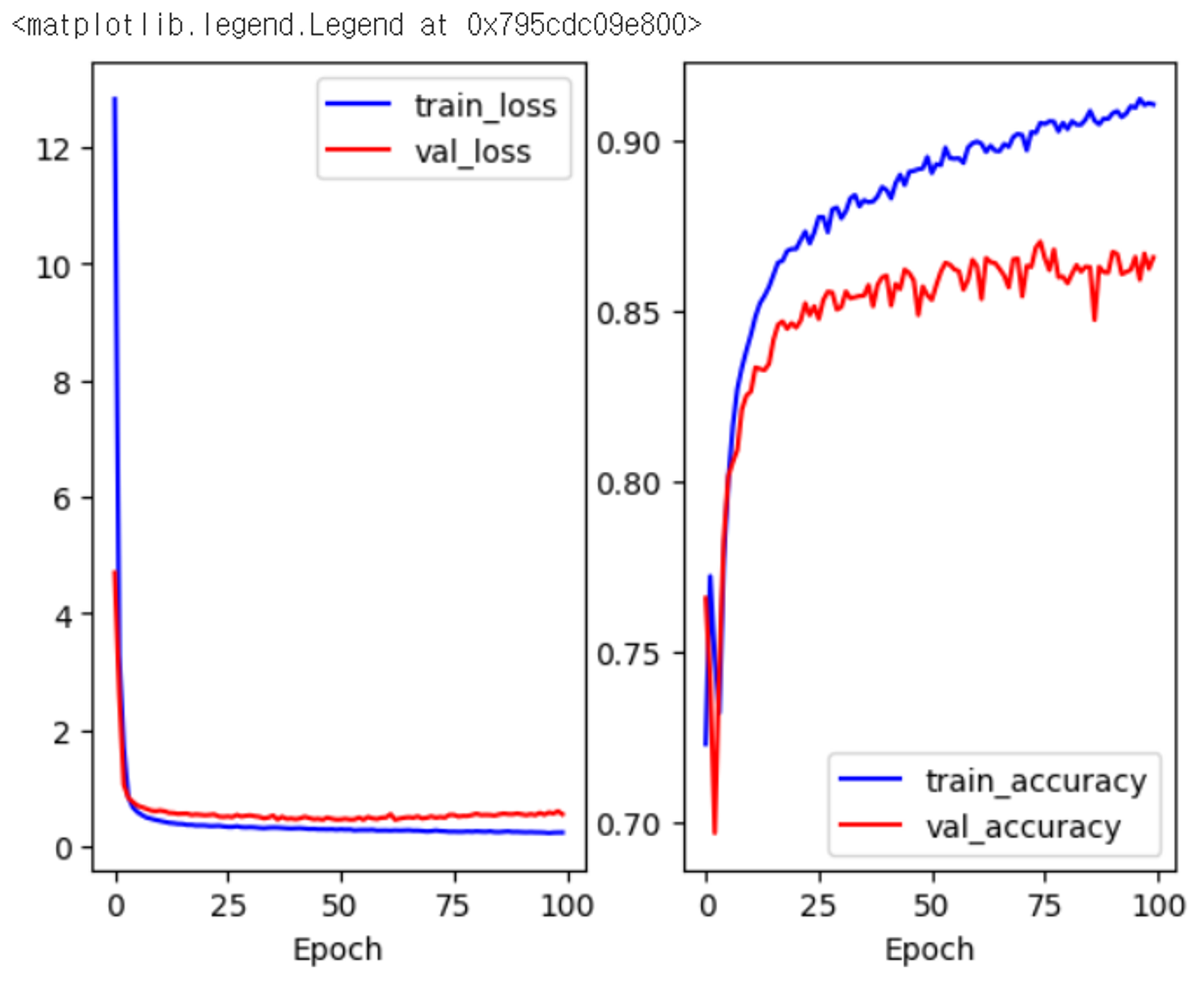
# X_test에 대한 평가 진행
model.evaluate(test_X, tf.keras.utils.to_categorical(test_y, num_classes = 10))
# 예측
y_pred = model.predict(test_X)
# 확률 값
y_pred[0].sum()
# => 0.9999994